[ad_1]
Controlling the language proficiency ranges in texts generated by giant language fashions (LLMs) is a big problem in AI analysis. Making certain that generated content material is suitable for varied proficiency ranges is essential for functions in language studying, training, and different contexts the place customers is probably not absolutely proficient within the goal language. With out efficient proficiency management, the usability and effectiveness of LLM-generated content material are considerably hindered, particularly for non-native audio system, youngsters, and language learners.
Present strategies to deal with this problem embody few-shot prompting, supervised finetuning, and reinforcement studying (RL). Few-shot prompting entails offering the mannequin with a number of examples to information its output, whereas supervised finetuning adjusts the mannequin utilizing a labeled dataset. RL, particularly Proximal Coverage Optimization (PPO), additional refined the mannequin’s outputs based mostly on a reward system. Nevertheless, these strategies have limitations: few-shot prompting with open-source fashions usually ends in excessive computational prices and suboptimal efficiency, and supervised fine-tuning requires intensive labeled knowledge, which is probably not available. Furthermore, RL methods might be unstable and computationally intensive, making them much less sensible for large-scale functions.
A workforce of researchers from Stanford and Duolingo suggest growing the CEFR-Aligned Language Mannequin (CALM), which mixes finetuning and PPO to align the output proficiency ranges with the Frequent European Framework of Reference for Languages (CEFR) requirements. This strategy particularly addresses the restrictions of current strategies by bridging the efficiency hole between proprietary fashions like GPT-4 and open-source options. CALM is designed to generate high-quality, proficiency-controlled content material at a fraction of the price of utilizing proprietary fashions. This represents a big contribution to the sphere by making proficiency-controlled textual content technology extra accessible and cost-effective.
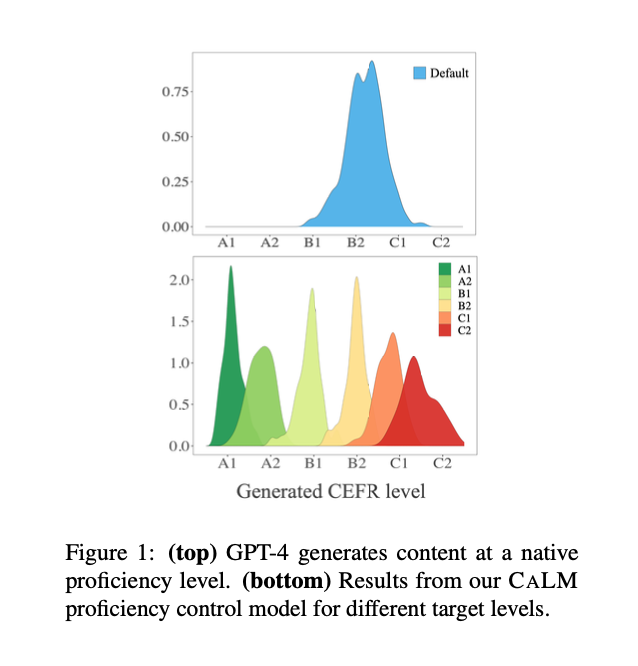
The proposed methodology entails finetuning open-source fashions resembling LLama-2-7B and Mistral-7B utilizing a dataset generated by efficient GPT-4 prompting methods. The dataset, known as TinyTolkien, consists of quick tales with various CEFR ranges. Additional coaching with PPO aligns the mannequin outputs with the specified proficiency ranges. Moreover, a sampling technique was launched to spice up mannequin efficiency by choosing the right output from a number of generations. The technical facets essential for understanding this strategy embody the usage of linguistic options for automated CEFR scoring and the appliance of RL methods to reduce ControlError, which measures the deviation of the generated textual content from the goal proficiency degree.
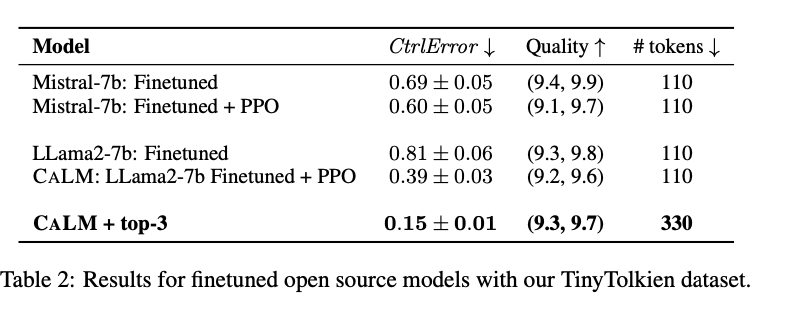
The outcomes exhibit that the proposed CALM mannequin achieves a ControlError corresponding to GPT-4 whereas considerably lowering prices. Analysis metrics included ControlError, QualityScore, and computational value. The findings had been validated via each automated scoring and a small-scale human research, which confirmed excessive scores for high quality and proficiency alignment. The important thing desk beneath compares varied prompting methods and fashions, highlighting CALM’s superior efficiency in each ControlError and high quality metrics. As an example, CALM with top-3 sampling achieved a ControlError of 0.15, outperforming different fashions and techniques.
In conclusion, the researchers addressed the crucial problem of controlling the proficiency degree of LLM-generated content material. They proposed a novel strategy combining finetuning and PPO, validated via rigorous analysis, which considerably advances the sphere by offering an environment friendly, cost-effective answer for producing proficiency-controlled textual content. This work has the potential to reinforce functions in training and language studying, making superior AI instruments extra accessible to a broader viewers.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 44k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]
Leave a Reply