[ad_1]
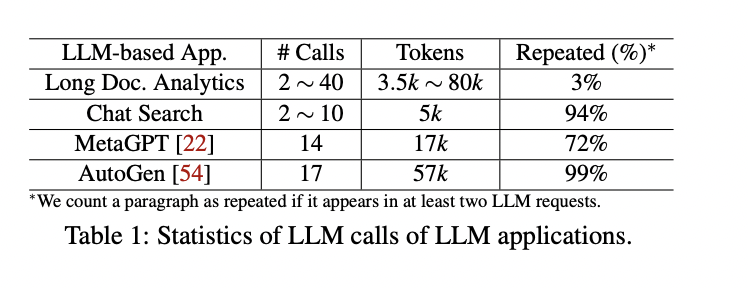
Giant language fashions (LLMs) possess superior language understanding, enabling a shift in utility improvement the place AI brokers talk with LLMs through pure language prompts to finish duties collaboratively. Functions like Microsoft Groups and Google Meet use LLMs to summarize conferences, whereas engines like google like Google and Bing improve their capabilities with chat options. These LLM-based functions typically require a number of API calls, creating complicated workflows. Present API designs for LLM companies are request-centric and lack application-level info, which leads to sub-optimal efficiency.
The sector of mannequin serving has seen important developments with methods like Clipper, TensorFlow Serving, and AlpaServe addressing deep studying deployment challenges. These methods give attention to batching, caching, and scheduling however typically overlook the distinctive wants of LLMs. Orca and vLLM enhance batching and reminiscence utilization for LLM requests. Parrot enhances LLM serving by analyzing application-level knowledge stream, and optimizing end-to-end efficiency. LLM orchestrator frameworks like LangChain and Semantic Kernel simplify LLM utility administration. Parrot integrates with these frameworks, using Semantic Variables for optimization. Parrot additionally makes use of DAG info to optimize LLM functions, emphasizing immediate construction and request dependencies.
Researchers from Shanghai Jiao Tong College and Microsoft Analysis proposed Parrot, an LLM service system designed to deal with LLM functions as first-class residents, retaining application-level info by means of using Semantic Variables. A Semantic Variable is a textual content area in a immediate with a selected semantic goal, corresponding to activity directions or inputs, and it connects a number of LLM requests. By exposing immediate constructions and request correlations, Parrot permits knowledge stream evaluation, optimizing end-to-end efficiency. Parrot’s unified abstraction facilitates joint optimizations, enhancing scheduling, latency hiding, and de-duplication.
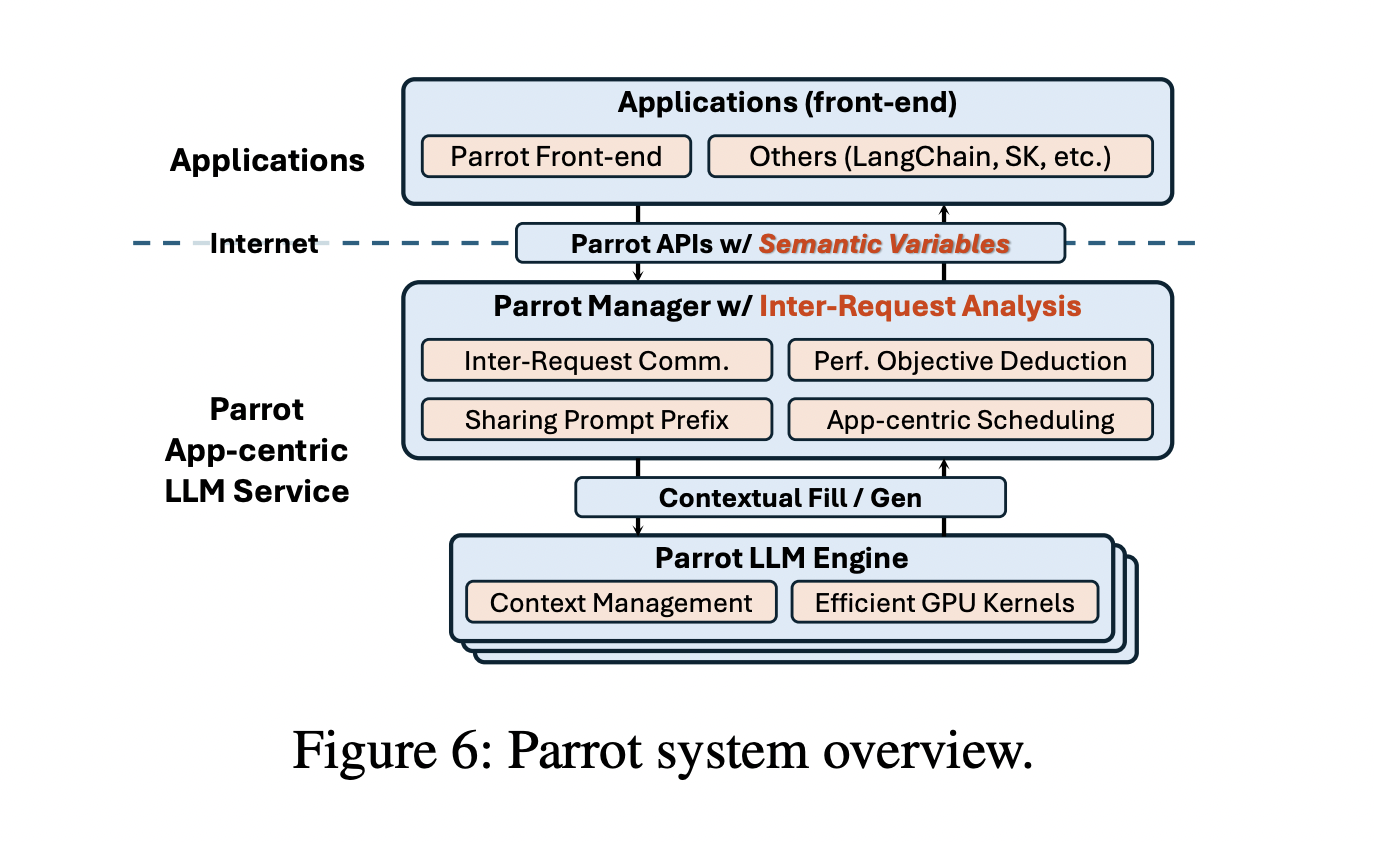
Parrot treats LLM requests as semantic capabilities carried out in pure language, executed by LLMs. Semantic Variables, outlined as enter or output placeholders in prompts, preserve the immediate construction for inter-request evaluation. In multi-agent functions, corresponding to MetaGPT, semantic capabilities like WritePythonCode and WriteTestCode use Semantic Variables to attach and sequence duties. Parrot’s asynchronous design permits submitting and fetching requests individually, facilitating just-in-time relationship evaluation. Efficiency standards will be annotated for every variable, optimizing and scheduling based mostly on end-to-end necessities like latency or throughput.
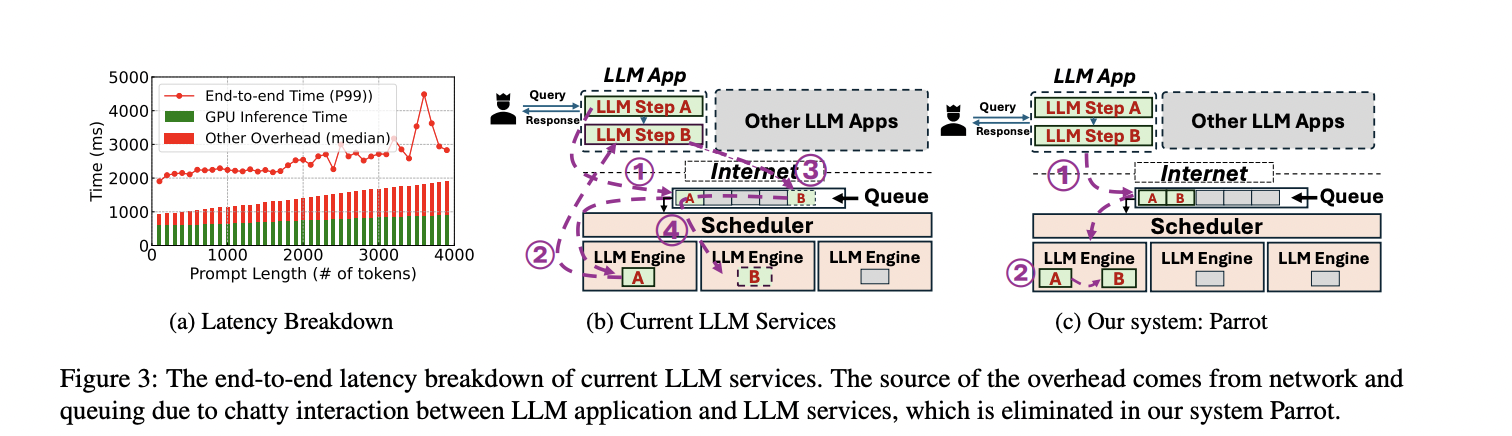
Evaluating Parrot on each manufacturing and open-source LLM-based functions reveals important enhancements, attaining as much as 11.7× speedup and 12× greater throughput in comparison with state-of-the-art options. These functions require quite a few LLM calls, resulting in excessive user-perceived latency. Treating requests individually can double end-to-end latency, however Parrot’s batching method eliminates this overhead. By scheduling consecutive requests collectively, Parrot straight feeds outputs from one step to the following, bypassing community and queuing delays.
This research introduces Parrot, which optimizes the end-to-end efficiency of LLM functions by treating them as first-class residents relatively than focusing solely on particular person requests. It introduces Semantic Variable, an abstraction that reveals dependencies and commonalities amongst LLM requests, creating new optimization alternatives. The analysis demonstrates Parrot can improve LLM-based functions by as much as 11.7×. This method opens new analysis instructions for enhancing scheduling options, corresponding to guaranteeing the equity of end-to-end efficiency in LLM functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.
[ad_2]
Leave a Reply